[DAOS] Rebuild介绍
daos: 2.6.0
1. 概述
在DAOS中,如果数据在不同target上进行多副本复制,一旦其中一个target发生故障,其数据将自动的在其他target上进行重建,因此数据冗余不会因为target故障而受到影响。
2. 重构检测
当某个target出现故障时,该target应被及时检测到并通知存储池的领导者,然后存储池的领导者会将该target从存储池中排除,并立即触发重建过程。
2.1. 目前情况以及长期目标
目前,由于Raft领导者无法自动排除target,系统管理员必须手动将目标从存储池中排除,这随后会触发重构。
在未来,领导者应该能够及时检测到故障target并自动触发重构,而无需系统管理员手动操作。
3. 重构过程
重构过程分为2个阶段:scan和pull。
3.1. Scan阶段
最初,领导者通过collective RPC向所有其他存活的target传播故障通知。任何接收到此RPC的targt将开始扫描其object table,以确定故障目标上丢失的冗余数据的对象。如果存在此类对象,则将其ID和相关的元数据发送到rebuild targets(rebuild initiators)。至于如何为故障target选择出rebuild target,将在placement/README.md中进行描述。
3.2. Pull阶段
一旦rebuild target获取到对象列表时,rebuild target将从其他副本中拉取这些对象的数据,然后在本地写入数据。每个target将向存储池领导者报告其重构状态,正在重构的对象,记录,是否完成等信息。一旦领导者得知所有的target都完成了扫描和重构阶段,它将通知所有的target,重构到此已完成,它们可以释放重构过程中占用的所有资源。
重构协议
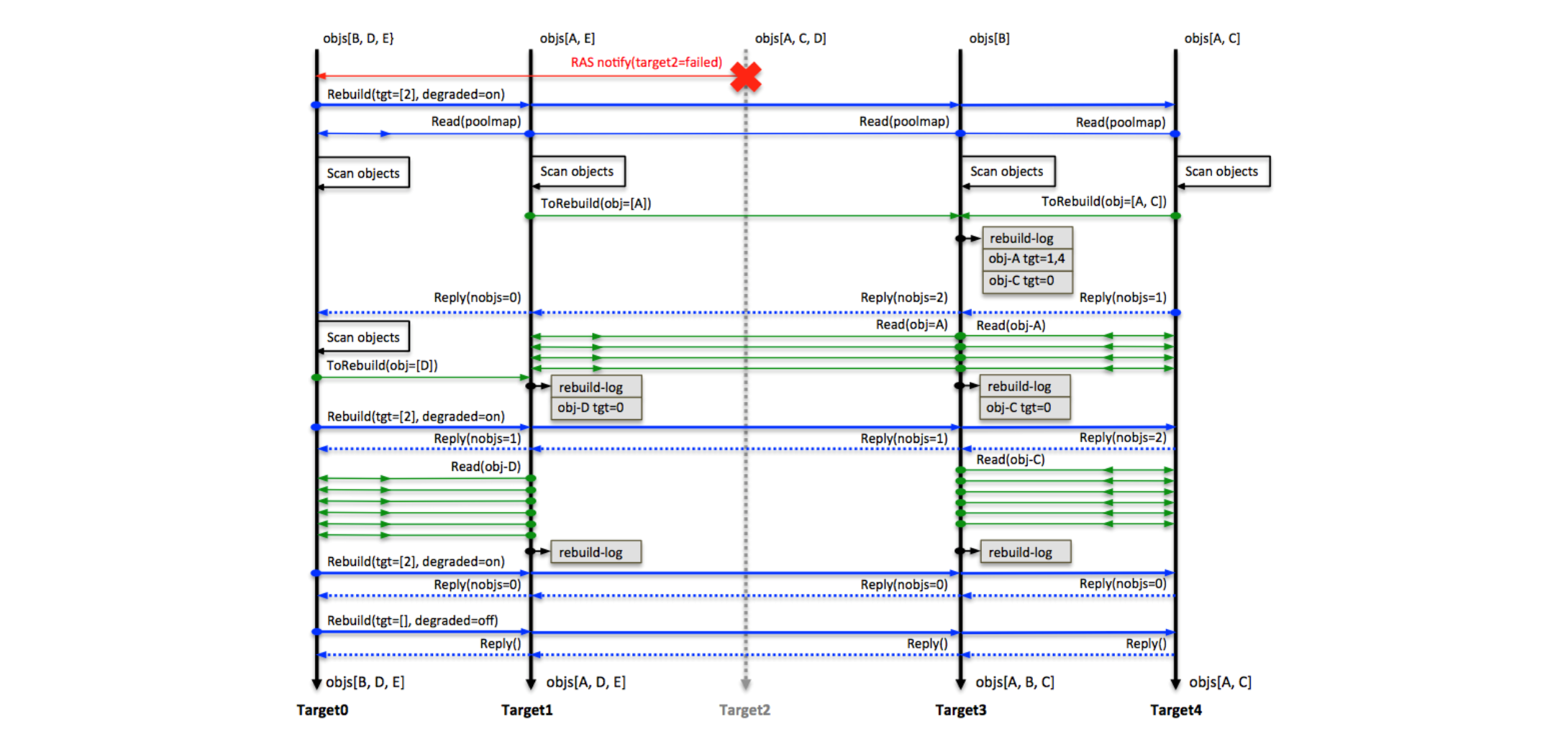
上图就是这个过程的一个示例:对象A有3个副本,对象B、C、D、E有2个副本。当target2发生故障时,最为Raft领导者的target0会向所有其他存活的targets广播故障信息,通知它们进入降级模式并进行扫描。(蓝色线实线表示领导者target向非领导者targets广播消息,蓝色虚线表示非领导者target向领导者target回复消息,绿色实线表示读取数据。)
- target0发现对象D丢失了一个副本,并计算出需要在target1上进行重构对象D的副本,因此它将对象D的ID及其元数据发送给了target1。
- target1发现对象A丢失了一个副本,并计算出需要在target3上进行重构对象A的副本,因此它将对象A的ID及其元数据发送给了target3。
- target4发现对象A和对象C都丢失了一个副本,并计算出需要在target3上进行重构对象A和C的副本,因此它将对象A和C的ID及其元数据发送给了target3。
- 在接收这些对象ID及其元数据后,target1和target3可以计算出这些需要重构的对象的存活副本,并通过从这些副本中提取数据来重构这些对象。
3.3. 多个targets重构
在大规模存储集群中,当前一次的故障还在重构中时,也可能还会出现多个故障。在这种情况下,DAOS既不应该同时处理这些故障,也不应该为了后面的故障修复而中断并重置之前的故障重构进度。否则,每次故障的重构耗时将显著增加,并且如果新的故障与正在进行的故障重构重叠了,重构可能永远不会结束。因此,对于多个故障,应该遵循以下规则。
- 如果重构发起者在重构过程中发生故障,则应该忽略在发起者上正在重构的对象分片,这将由下一次重构处理。
- 如果重构发起者无法从其他副本获取数据,他将从其他可用的副本上获取数据。
- 在重构期间,如果已经发生了另外一个故障,那么对于当前正在修复的故障,正在参与重构的target无需再重新扫描其对象或重置其重构进度。
- 当出现多个故障时,如果来自不同容灾域的故障targets的数量已经超过了容错级别,可能出现不可恢复的错误,应用程序可能会遭受数据丢失。在这种情况下,上层堆栈软件向缺失数据的对象发送I/O时可能会看到错误。
多故障协议
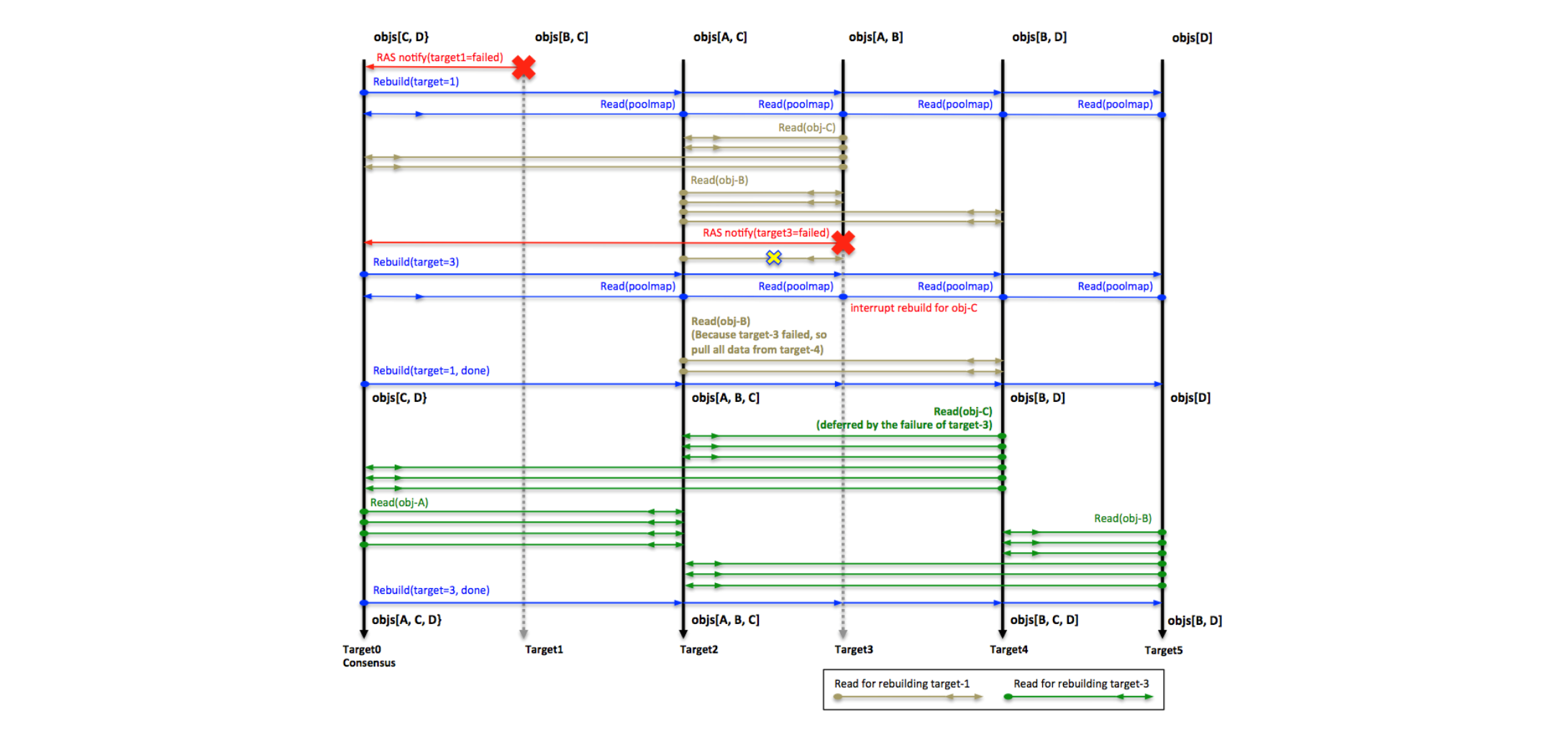
- 在这个例子中,对象A是2副本,对象B、C、D是3副本。
- target1失败后,target2是重构对象B的发起者,它正在从target3和target4中拉取数据。target3是重构对象C的发起者,它正在从target0和target2中拉取数据。
- target3在target1完成成功之前发生故障了,因此此时应该放弃对象C的重构,因为target3是其发起者。对象C缺失的数据将在重构target3时重新构建。
- 因为target3也是重构对象B的贡献者,根据协议,对象B的发起者target2应将重构从target3切换到target4上。
- 在重构target3过程中,target4是重构对象C的发起者。
如果有多个存储池受到故障目标的影响,这些存储池可以同时被重构。
4. 重构期间的I/O
如果在重构期间存在并发写入,重构协议应确保新写入的数据永远不会丢失。这些写入的数据要么直接被存储在新的对象分片中,要么写入到rebuild target拉取的对象分片中。并且还应该保证获取操作能够得到正确的数据。为了实现这些目标,应该遵守以下协议:
- 获取操作将始终跳过正在重构的target。
- 只有所有的对象分片的更新都成功完成后,更新才算真正的完成。
- 如果这些更新操作中任何一个失败,客户端将无限重试,直到成功,或者pool map提示target出现故障。在第二种情况,客户端将切换到新的pool map,并将更新发送给新的rebuild target。
- 普通I/O与重构过程不是同步的,因此在重构过程中,数据可能会被rebuild target和普通I/O重复写入。
5. 重构资源限流
在重构期间,用户可以设置节流阀,以确保重构过程不会使用比用户设置的更多的资源。目前,用户只能设置CPU周期。例如,如果用户将节流阀设置为50,那么重建过程最多将使用50% 的CPU周期来执行重建任务。默认情况下,节流阀为30。
6. 重构状态
如前文所述,每个target将通过IV向存储池领导者报告其重建状态,然后领导者将汇总所有targets的重建状态,并以每2s打印一次整体重构状态。
Rebuild [started] (pool 8799e471 ver=41)
Rebuild [scanning] (pool 8799e471 ver=41, toberb_obj=0, rb_obj=0, rec= 0, done 0 status 0 duration=0 secs)
Rebuild [queued] (419d9c11 ver=2)
Rebuild [started] (pool 419d9c11 ver=2)
Rebuild [scanning] (pool 419d9c11 ver=2, toberb_obj=0, rb_obj=0, rec= 0, done 0 status 0 duration=0 secs)
Rebuild [pulling] (pool 8799e471 ver=41, toberb_obj=75, rb_obj=75, rec= 11937, done 0 status 0 duration=10 secs)
Rebuild [completed] (pool 419d9c11 ver=2, toberb_obj=10, rb_obj=10, rec= 1026, done 1 status 0 duration=8 secs)
Rebuild [completed] (pool 8799e471 ver=41, toberb_obj=75, rb_obj=75, rec= 13184, done 1 status 0 duration=14 secs)
上述日志中显示,有2个存储池正在被重构(8799e471和419d9c11)。其中倒数第三行表示存储池8799e471正在被重构,并且已经完成75个对象,但是records只完成11937。
在重构过程中,如果客户端向存储池领导者查询存储池状态,存储池领导者会将其重构状态返回给客户端。
7. 重构失败
如果由于某些故障导致重构失败,重构将被中止,相关日志如下:
Rebuild [aborted] (pool 8799e471 ver=41, toberb_obj=75, rb_obj=75, rec= 11937, done 1 status 0 duration=10 secs)
8. 重构过程中的校验和
在重构期间,正在进行重构的server将充当DAOS客户端角色,即它会从副本server读取数据和校验和,并在将数据用于重构之前验证该数据的完整性。如果检测到损坏的数据,读取操作将失败,并且该副本server将会收到数据损坏的通知。然后重构操作将尝试选择使用其他副本。
对象list和fetch task API提供了校验和iov参数。这是为重构提供可用于打包校验和的内存。否则,重构在写入本地VOS实例时将不得不重新计算校验和。如果缓冲区中可分配的内存不足,iov_len将设置为所需容量,并且打包到缓冲区中的校验和也将被截断。
以下描述了在重构过程中一个校验和的生命周期中的“接触点(touch points)”。此处包含客户端task APIs以及packing/unpacking信息,因为重构是这些使用校验和的API的主要用户。
8.1. Rebuild Touch Points
migrate_fetch_update_(inline|single|bulk):即rebuild/migrate相关函数,负责写入本地VOS中,同时必须确保校验和也被写入。这些函数必须使用checksum iov参数进行获取以得到校验和,然后将校验和解包到iod_csum中。obj_enum.c:用于枚举要重构的对象。由于fetch_update函数会从提取操作中解包出校验和,也会为枚举操作解包校验和,因此obj_enum.c中的解包过程会简单的将csum_iov复制到enum_unpack_recxs的io结构(dc_obj_enum_unpack_io)中,然后在migrate_one_insert中深度复制到mrone(migrate_one)结构中。
8.2. Client Task API Touch Points
dc_obj_fetch_task_create:将校验和iov设置为daos_obj_fetch_t参数。这些参数被设置为rw_cb_args.shard_args.api_args,并通过cli_shard.c中的访问器函数(rw_args2csum_iov)进行访问,以便rw_args_store_csum可以轻松地访问它。这个函数会将从server中接收到校验和打包到iov中。dc_obj_list_obj_task_create:将校验和iov设置为daos_obj_list_obj_t参数。然后将args.args.csum复制到dc_obj_shard_list中的obj_enum_args.csum。在枚举回调函数dc_enumerate_cb中,已经打包的校验和缓存数据将从rpc参数复制到obj_enum_args.csum(其指向与调用者相同的缓冲区)
8.3. Packing/unpacking checksums
当校验和被打包时(无论是fetch还是list操作),只有数据的校验和被包括在内。对于object list操作,只有内联数据的校验和会被包括在内。在重构期间,如果数据不是内联的,则重构过程会获取其余数据并获取校验和。
ci_serialize:通过将结构体追加到iov中,然后将校验和信息缓冲数据追加到iov中来打包校验和。这会将实际的校验和放在描述该校验和的校验和结构之后。ci_cast:解包校验和以及描述结构。它通过将iov缓冲区强制转换成dcs_csum_info结构体,并将csum_info的校验和指针设置为指向结构体之后的内存来实现这一点。它不复制任何内容,实际上只是进行强制类型转换。要获取所有的dcs_csum_infos,调用者需要先对iov进行强制类型转换,将csum_info复制到目标位置,然后移动到iov中的下一个csum_info中。由于这个过程会修改iov结构,因此最好使用iov的副本作为临时结构。