[Ceph 14.2.22] 使用deploy部署多机集群
1. 前言
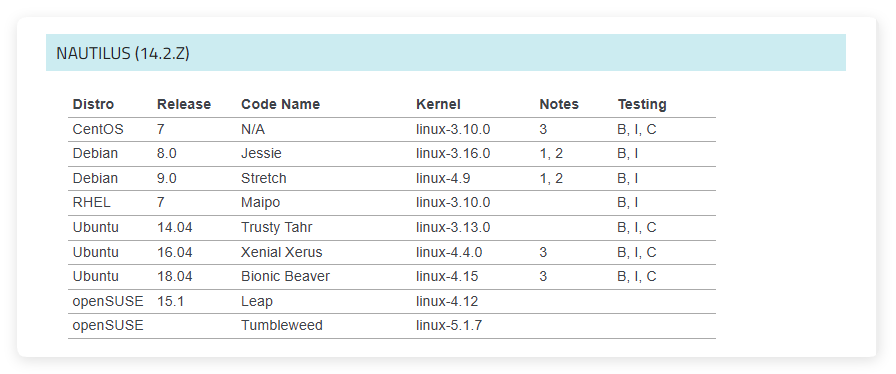
上表中是 Ceph 官方文档给出的 Ceph 14 系列的系统和内核推荐,其中在 centos 7、ubuntu 14.04、ubuntu 16.04、ubuntu 18.04 上都做了完整的测试。本文将介绍如何在ubuntu 18.04中使用 ceph-deploy 部署 ceph 集群,ceph 版本为14.2.22。
2. 基础集群部署
2.1. 基础集群规划
node name node ip component name
---------------------------------------------------------
admin 192.168.3.14 [ceph-deploy]
node0 192.168.3.10 [mon.node0, mgr.node0, osd.0]
node1 192.168.3.11 [mon.node1, mgr.node1, osd.1]
node2 192.168.3.12 [mon.node2, mgr.node2, osd.2]
上述 node0 node1 node2 是集群节点,每个节点都会部署 mon 服务、mgr 服务以及 osd 服务
除了 osd 服务外,ceph-deploy 不支持在同一个节点上部署多个同类别的 ceph 服务(mon、mgr、mds、rgw)。因此如果需要部署多个同类别的服务,只能在其他节点上部署。如果不使用 ceph-deploy 来部署集群,可以通过手动部署方式来实现在同一节点上部署多个同类别的服务。对于手动部署方式而言是没有任何限制的。
2.2. 环境配置
2.2.1. 关闭防火墙
在集群所有节点(node0 node1 node2)上执行以下命令:
systemctl stop ufw.service
systemctl disable ufw.service
2.2.2. 设置时间同步
在 ceph 集群中,osd 进程心跳机制,mon 进程维护集群 map,要求每个主机之间时间同步,否则会影响集群。在 ubuntu 系统上可以安装 ntp 服务和 ntpdate 客户端工具实现时间同步。在集群节点中只需要一个 ntp 服务,其他集群节点安装 ntpdate 客户端工具即可。
在 node0 节点上安装 ntp 服务:
apt install ntp
在 node1 node2 上安装 ntpdate 客户端:
apt install ntpdate
以上将 node0 作为 ntp 服务端,node1 node2 为 ntp 客户端,node1 node2 通过 ntpdate 工具实现与 node0 时间同步。
2.2.3. 设置 ssh 免密码登录
ceph-deploy 在部署 ceph 集群时,是通过 ssh 方式登录到不同节点上,然后执行一系列指令。由于 ceph-deploy 是完全自动化脚本,在部署 ceph 集群时,是不支持交互式操作。当使用 ssh 登录到集群中某个节点时,要求输入远程节点的密码,因此必须要设置 ssh 免密登录。同时 ceph-deploy 中使用了大量的 sudo 权限的指令,而普通用户执行 sudo 时必须要输入密码,为了省去该麻烦,建议直接使用 root 用户来操作。
修改/etc/hosts
在 admin 节点的 /etc/hosts 文件中追以下内容:
192.168.3.11 node0
192.168.3.12 node1
192.168.3.13 node2
192.168.3.14 admin
一定要确保每个节点上的 hostname 和上述配置文件中的 hostname 相同,如果没有更改 hostname,可以使用 hostnamectl set-hostname 命令来修改。
生成 ssh key
在 admin 节点上执行 ssh-keygen 命令,一路回车,不要输入任何东西。
将 ssh key 拷贝到所有集群节点上
在 admin 节点上执行以下命令:
ssh-copy-id node0
ssh-copy-id node1
ssh-copy-id node2
通过以上步骤,就可以直接用 ssh node0 方式直接远程登录集群中其他节点上,而不用输入用户名和密码。
2.2.4. 添加 ceph apt 源
为了加快下载速度,此处使用阿里云开源镜像站。
在 admin 节点上执行以下命令:
echo "deb [trusted=yes] https://mirrors.aliyun.com/ceph/debian-nautilus/ $ (lsb_release -cs) main" > /etc/apt/sources.list.d/ceph.list
trusted=yes表示临时禁用 GPG 验证,从而避免必须添加 ceph release.asc 密钥。
2.2.5. 安装 ceph-deploy
使用 ceph-deploy 部署 ceph 集群,需要先安装 ceph-deploy 工具。ubuntu 已经自带了 ceph-deploy 安装包,但该版本不一定支持 ceph 14.2.22 版本,需要从 ceph 官方下载支持 ceph 14.2.22 版本的 ceph-deploy 工具。上文已经将 ceph nautilus 版本的 apt 源添加到系统中,所以可以直接使用 apt 命令安装。
在 admin 节点上执行以下命令:
apt update
apt install ceph-deploy=2.0.1
2.3. 安装部署
如果之前已经安装了 ceph,无论是哪个版本的,请按照 集群卸载 步骤执行集群清理操作。
2.3.1. 创建临时目录
ceph-deploy 在部署 ceph 集群过程中会产生一些日志文件、配置文件以及 ceph 必备的文件。为了方便管理,建议创建一个临时目录来存放这些文件。
在 admin 节点上执行以下命令:
mkdir cluster
之后所有关于 ceph-deploy 的操作都必须在上述cluster目录下执行。
2.3.2. 安装 ceph 软件
在 admin 节点上执行以下命令:
ceph-deploy install node0 node1 node2 \
--repo-url=https://mirrors.aliyun.com/ceph/debian-nautilus \
--nogpgcheck
上述命令将在 node0 node1 node2 上安装 ceph 相关的软件,可以同时指定多个 hostname。其中 --repo-url 是 ceph 软件仓库的地址,--nogpgcheck 是绕开 gpg 认证。默认情况下,ceph-deploy 安装脚本中指定的是 ceph 13 版本的地址,所以需要重新指定为 ceph 14 版本的地址。
2.3.3. 初始化集群
在 admin 节点上执行以下命令:
ceph-deploy new node0 node1 node2
上述命令将会初始化集群的 config 和 keyring,并初始化集群 mon 服务的名字为mon.node0 mon.node1 mon.node2。该命令可以同时指定多个 mon 节点 hostname。
2.3.4. 创建 mon
在 admin 节点上执行以下命令:
ceph-deploy mon create-initial
上述命令将会初始化所有的 mon 服务的数据(比如 keyring),可以在 /var/lib/ceph/mon/ 目录下查看。初始化后会启动所有的 mon 服务。
2.3.5. 创建 mgr
在 admin 节点上执行以下命令:
ceph-deploy mgr create node0 node1 node2
上述命令将会初始化所有的 mgr 服务的数据(比如 keyring),可以在 /var/lib/ceph/mgr/ 目录下查看。初始化后会启动所有的 mgr 服务。
2.3.6. 创建 osd
ceph 支持 2 种存储引擎:bluestore和filestore。filestore 模式下,可以看到数据存在哪个目录下,而 bluestore 则无法看到。filestore 是一个过时的技术,在后续版本中逐渐被 Ceph 弃用,filestore 已经没有任何研究价值,因此本文默认以 bluestore 为准。
在 admin 节点上执行以下命令:
ceph-deploy osd create --bluestore --data /dev/sdb node0
ceph-deploy osd create --bluestore --data /dev/sdb node1
ceph-deploy osd create --bluestore --data /dev/sdb node2
上述命令将分别使用 node0 节点上的 sdb 磁盘创建和启动 osd.0 服务,node1 节点上的 sdb 磁盘创建和启动 osd.1 服务,node2 节点上的 sdb 磁盘创建和启动 osd.2 服务。一定要确保每个节点上都有 sdb 这块磁盘,如果没有,那么要根据实际情况进行调整。osd 服务的数据存储在 /var/lib/ceph/osd/ 目录下。
ceph-deploy 默认使用了 ceph-volume lvm 方式来创建 osd,ceph-volume lvm 是通过创建逻辑卷来管理磁盘,而不是直接来管理磁盘。可以使用 lvdisplay 命令查看所有的 osd 逻辑卷信息。
2.3.7. 分发 key 和 config 文件
ceph 通过 ceph 命令来管理集群,如果想要使用 ceph 命令,需要将相关的 key 文件和 config 文件放到 /etc/ceph 目录下。
在 admin 节点上执行以下命令:
ceph-deploy admin node0 node1 node2
上述命令将 key 文件和 config 文件分发到 node0 node1 node2 节点上。该命令可以同时指定多个 hostname。
2.3.8. 查看集群状态
在上述分发的任意的一个集群节点(node0 node1 node2)上执行ceph -s便可以查看到集群的状态信息。
ceph -s
---------
cluster:
id: 4a7760d1-22b6-49d3-8236-31962c941632
health: HEALTH_WARN
mon is allowing insecure global_id reclaim
services:
mon: 1 daemons, quorum node0,node1,node2 (age 3m)
mgr: node0(active, since 3m), standbys: node1, node2
osd: 3 osds: 3 up (since 80s), 3 in (since 80s)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 12 GiB / 15 GiB avail
pgs:
结果显示,该集群中 mon 服务有 3 个且状态正常,mgr 服务有 3 个且状态正常,osd 服务有 3 个且状态正常。目前集群没有任何数据。
3. 块存储集群部署
3.1. 创建 rbd pool
在集群任意一个节点(node0 node1 node2)上执行以下命令:
ceph osd pool create rbd_pool 1 1
上述命令将创建一个名为 rbd_pool 的存储池,其中1 1分别是 pg 和 pgp 的数量,因为是测试集群,所以都设置为 1。可以通过 ceph osd pool ls detail 命令查看存储池的详细信息。
3.2. 创建 rbd image
在集群任意一个节点(node0 node1 node2)上执行以下命令:
rbd create --pool rbd_pool --image image1 --size 1024 --image-format 2 --image-feature layering
上述命令将在名为 rbd_pool 的存储池中划出 1024 字节大小的存储空间来创建为名 image1 的 rbd image。可以使用 rbd ls rbd_pool 命令来查看 rbd_pool 中已经创建了哪些 rbd image。
3.3. 使用 rbd image
rbd image 最普通的使用场景是在客户端节点上将 image 映射成内核块设备,这样就可以像使用磁盘一样来使用 rbd image。
3.3.1. 映射 rbd image 到系统块设备
实际上应该在客户端节点上来映射 rbd image。本文为了测试,就直接复用集群节点。
在 node0 节点上执行以下命令:
rbd map --pool rbd_pool --image image1
可以通过 rbd showmapped 命令来查看 rbd image 被映射成的内核块设备的名字是什么。
rbd showmapped
----------------
id pool namespace image snap device
0 rbd_pool image1 - /dev/rbd0
从结果显示 rbd_pool 数据池中的镜像 image1 已经被映射到成一个名为 rbd0 的内核块设备。
3.3.2. 格式化 rbd 块设备
在 node0 节点上执行以下命令:
mkfs.ext4 -m0 /dev/rbd0
3.3.3. 挂载 rbd 块设备
在 node0 节点上执行以下命令:
mount /dev/rbd0 /mnt/rbd
其中/mnt/rbd是挂载路径。至此,就可以在 /mnt/rbd 目录下正常读写文件。
4. 文件存储集群部署
4.1. 文件存储集群规划
node name node ip component name
---------------------------------------------------------
admin 192.168.3.14 [ceph-deploy]
node0 192.168.3.10 [mon.node0, mgr.node0, mds.node0, osd.0]
node1 192.168.3.11 [mon.node1, mgr.node1, mds.node1, osd.1]
node2 192.168.3.12 [mon.node2, mgr.node2, mds.node2, osd.2]
上述集群规划是在前文 基础集群规划 的基础上增加了 mds 服务,每个集群节点上都增加 1 个 mds 服务。
4.2. 创建 mds 服务
在 admin 节点上执行以下命令:
ceph-deploy --overwrite-conf mds create node0 node1 node2
上述命令将在 node0 节点上创建并启动名为 mds.node0 的 mds 服务,在 node1 节点上创建并启动名为 mds.node1 的 mds 服务,在 node2 节点上创建并启动名为 mds.node2 的 mds 服务。其中添加 --overwrite-conf 参数后就可以直接将新的 ceph.conf 内容覆盖到/etc/ceph/conf 目录下。如果不添加该参数,需要手动 cp。
4.3. 创建存储池
ceph 的文件系统在架构设计上将文件的数据和文件的元数据分开存储,因此需要创建 2 个存储池:data pool 和 metadata pool。data pool 用于存储文件的数据,matadata pool 用于存储文件的元数据。
4.3.1. 创建 data pool
在集群任意一个节点(node0 node1 node2)上执行以下命令:
ceph osd pool create cephfs_data 1 1
上述命令将创建一个名为 cephfs_data 的存储池,其中 1 1 分别表示 pg 和 pgp 的数量,因为是测试,所以都设置为 1。
4.3.2. 创建 metadata pool
在集群任意一个节点(node0 node1 node2)上执行以下命令:
ceph osd pool create cephfs_metadata 1 1
上述命令将创建一个名为 cephfs_metadata 的存储池,其中 1 1 分别表示 pg 和 pgp 的数量,因为是测试,所以都设置为 1。
4.4. 创建文件系统
在集群任意一个节点(node0 node1 node2)上执行以下命令:
ceph fs new cephfs cephfs_metadata cephfs_data
上述命令将会创建一个名为 cephfs 的文件系统(也可以理解成文件系统的一个命名空间),元数据池一定要写在数据池之前。创建好的文件系统可以通过 ceph fs ls 命令查看。
4.5. 使用文件系统
文件系统使用的方式比较单一:在需要使用 Ceph 文件存储系统的客户端上挂载 cephfs 到挂载目录,然后向操作普通目录一样读写文件。Linux 挂载 Ceph 文件系统有 2 种方式:内核态和用户态。本文采用用户态方式(ceph-fuse)挂载。
4.5.1. 挂载文件系统
实际上应该在客户端节点上来挂载 cephfs。本文为了测试,就直接复用集群节点。
在 node0 节点上执行以下命令:
ceph-fuse -m 192.168.3.10 /mnt/cephfs
上述命令默认是以 client.admin 用户来挂载的,也可以通过 -n 参数来指定使用 Ceph 哪个用户来挂载。但无论是使用谁,必须要确保客户端节点的/etc/ceph 目录下有 ceph 的 config 和 keyring 文件,否则无法与 mon 建立连接。
至此,就可以在 /mnt/cephfs 目录下正常读写文件。
5. 对象存储集群部署
5.1. 对象存储集群规划
node name node ip component name
---------------------------------------------------------
admin 192.168.3.14 [ceph-deploy]
node0 192.168.3.10 [mon.node0, mgr.node0, rgw.node0, osd.0]
node1 192.168.3.11 [mon.node1, mgr.node1, rgw.node1, osd.1]
node2 192.168.3.12 [mon.node2, mgr.node2, rgw.node2, osd.2]
上述集群规划是在前文 基础集群规划 的基础上增加了 rgw 服务,每个集群节点上都增加 1 个 rgw 服务。
5.2. 创建 rgw 服务
在 admin 节点上执行以下命令:
ceph-deploy --overwrite-conf rgw create node0 node1 node2
上述命令将在 node0 节点上创建并启动名为 rgw.node0 的 rgw 服务,在 node1 节点上创建并启动名为 rgw.node1 的 rgw 服务,在 node2 节点上创建并启动名为 rgw.node2 的 rgw 服务。其中添加 --overwrite-conf 参数后就可以直接将新的 ceph.conf 内容覆盖到/etc/ceph/conf 目录下。如果不添加该参数,需要手动 cp。
5.3. 配置 rgw
5.3.1. 配置 admin_socket
在 ceph 14 版本中,可以使用 ceph daemon 命令来查看运行中的 ceph 服务的所有配置,比如 ceph daemon osd.0 show。该命令能自动查找本地 /var/run/ceph/ 目录下的相匹配的 socket 进程,虽然 rgw 服务的 socket 进程文件也在该目录下,但是 ceph daemon 命令无法自动识别,每次使用时必须要手动指定 rgw socket 文件完整路径。为了避免这种情况,可以在配置文件中直接指定,然后可以不用手动指定 rgw socket 文件路径就可以使用了。
修改 admin 节点 cluster/ceph.conf 文件
[client.rgw.node0]
admin_socket = /var/run/ceph/ceph-client.rgw.node0.asok
[client.rgw.node1]
admin_socket = /var/run/ceph/ceph-client.rgw.node1.asok
[client.rgw.node2]
admin_socket = /var/run/ceph/ceph-client.rgw.node2.asok
5.3.2. 配置 rgw_frontends
在 Ceph 14 版本中,rgw 支持 2 种 HTTP 前端来提供对象存储 web 服务,分别是 civetweb 和 beast。CivetWeb 是一个轻量级的嵌入式 Web 服务器,功能相对简单,性能在高并发场景下不如 Beast。Beast 是基于 Boost.Beast 库的新一代 HTTP 前端,旨在替代 CivetWeb。Beast 提供更完善的 TLS/SSL 支持,支持更高的并发性能和更低的延迟,更适合生产环境。默认情况下 Ceph 14.2.22 中的 rgw 采用 beast 作为 web 服务,端口为 7480。如果有需要,可以通过修改 /etc/ceph/ceph.conf 文件来指定 rgw 使用哪种 web 服务,此处以 civetweb 为案例:
修改 admin 节点 cluster/ceph.conf 文件
[client.rgw.node0]
rgw_frontends = "civetweb port=7480"
[client.rgw.node1]
rgw_frontends = "civetweb port=7480"
[client.rgw.node2]
rgw_frontends = "civetweb port=7480"
修改 admin 节点的 ceph.conf 文件后,需要将该文件分发到集群部署了 rgw 服务的节点的 /etc/ceph 目录下,同时必须重启对应的 rgw 服务才可以生效。上述修改了 rgw.node0 rgw.node1 rgw.node2 服务的配置,因此这 3 个服务都要重启。
5.4. 重启 rgw 服务
在所有部署了 rgw 服务的节点上执行以下命令:
systemctl restart ceph-radosgw.target
上述命令只会重启当前节点上的所有 rgw 服务,比如当前节点是 node0,该命令会重启 node0 节点上的所有 rgw 服务,但不会重启其他节点上的 rgw 服务。
5.5. 测试访问
在集群任意一个节点(node0 node1 node2)上执行以下命令:
curl http://node0:7480
------------------------
<?xml version="1.0" encoding="UTF-8"?>
<ListAllMyBucketsResult xmlns="http://s3.amazonaws.com/doc/2006-03-01/">
<0wner>
<ID>anonymous</ID>
<DisplayName></DisplayName>
</0wner>
<Buckets></Buckets>
</ListALLMyBucketsResult>
上述结果表示在任何一个节点上访问 rgw web 服务时,都可以收到正常回应,也就说明对象存储集群已经正常对外提供服务。
5.6. 使用对象存储
Ceph 的对象存储在架构上设计区别于文件系统和块存储,其目的为海量、非结构化、高持久性、跨网络共享的数据而生。它不能像文件系统一样直接在本地挂载使用,因为它放弃了目录树和随机读写能力,采用扁平化方式来存储对象,以达到无限扩展性和简单性。“本地直接访问”违背对象存储的设计哲学:它的价值在于分布式、持久化、低成本地存储海量非结构化数据,而不是提供低延迟本地 I/O。
另外,HTTP 是无状态协议,rgw 实例可以水平扩展,请求可被任意节点处理。HTTP 的请求-响应模型天然适合这种“一次传完”的模式。其次,AWS S3 定义了对象存储的事实标准,几乎所有的对象存储客户端都支持 S3 协议,因此 Cpeh rgw 实现了 S3 接口,其目的就是为了无缝融入现有生态。
所以 Ceph 对象存储的使用应该要遵循 S3 协议。
5.6.1. 创建 s3 用户
在集群任意一个节点(node0 node1 node2)上执行以下命令:
radosgw-admin user create --uid=s3user --display-name=s3user --access-key s3user123 --secret s3user123
上述命令将会创建名为 s3user 的对象存储用户。其中 --uid 的值是用户名,--display-name 的值是对外显示的用户名。--access-key 和 --secret 参数用于设置 key,这两个参数不是必须的。
5.6.2. 访问对象存储
有很多对象存储客户端工具,比如 s3cmd、s3browser。s3browser 是最常用的 windows 工具,本文也将以 s3browser 为案例。
添加 s3 用户
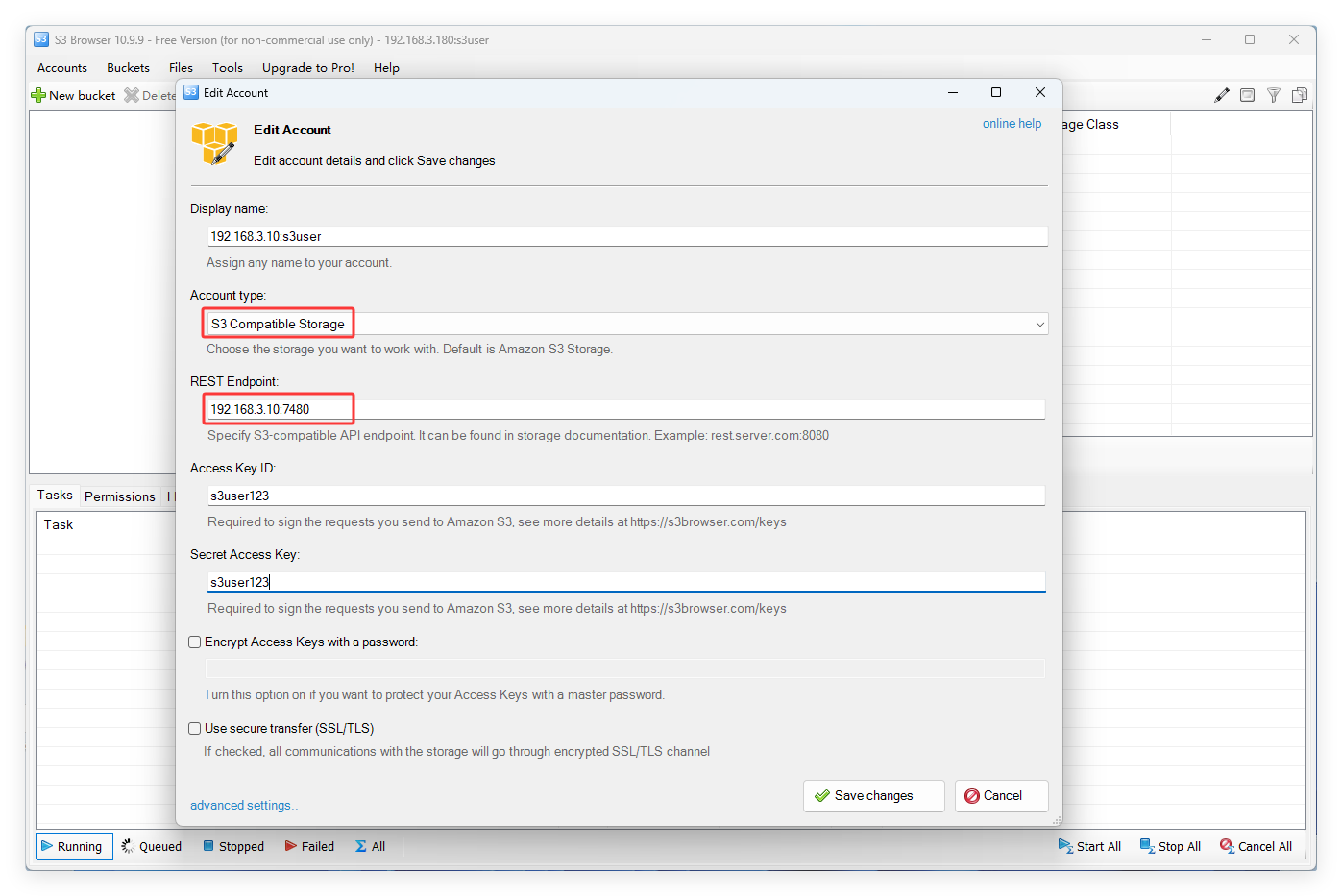
display name:s3browser 工具中显示的用户名,随便写,不一定要和上述创建的用户名一样!account type:必须要选则 s3 compatible storage!rest endpot:rgw 对外提供 web 服务的地址,一般是主 rgw 的 ip 地址和端口号,端口号不能缺少!access key id和secret access key一定要和上述创建用户时的一一对应。
添加 bucket
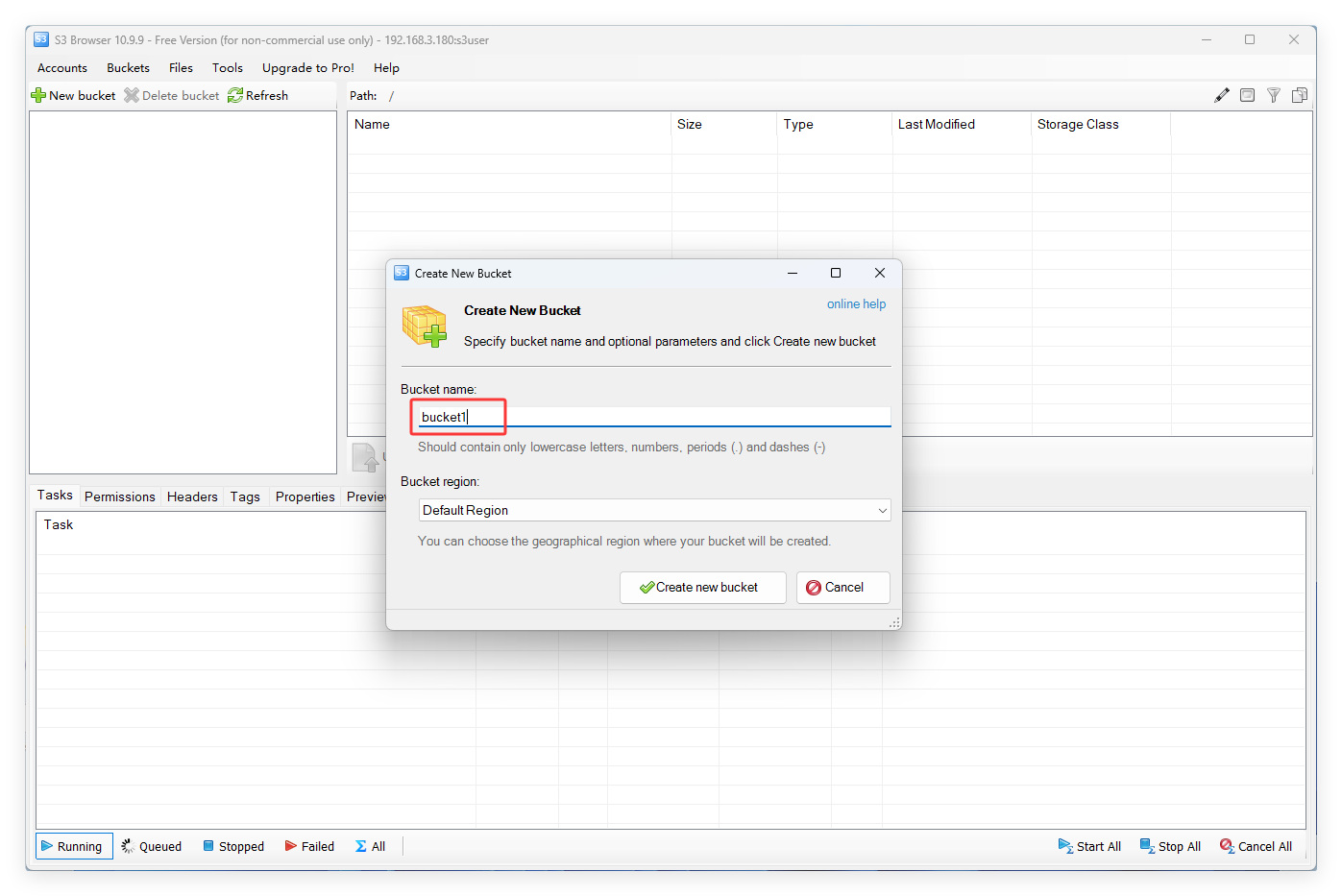
bucket 名字随便写,没有规范和要求。
上传文件
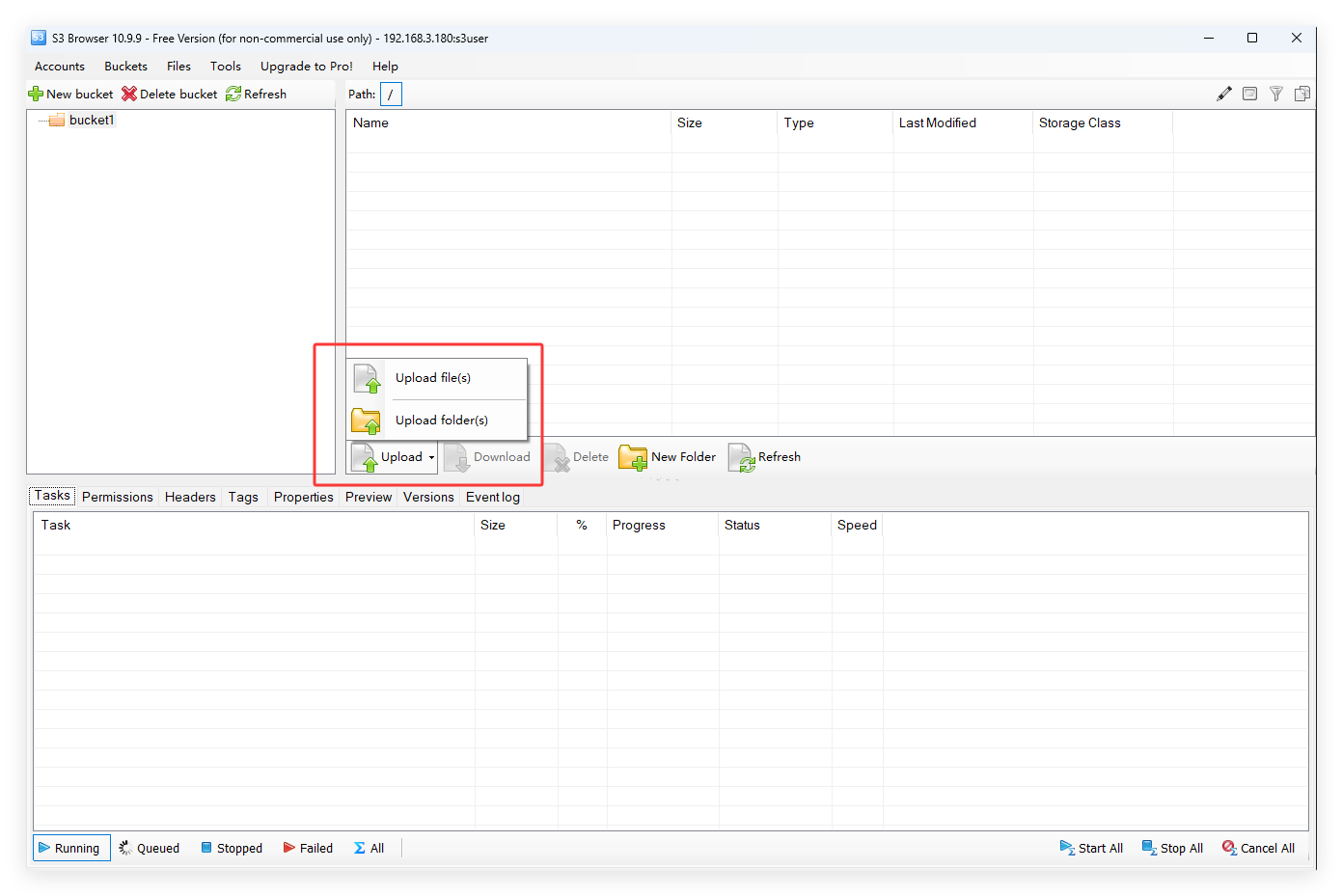
如果上述都没有任何问题,那就表示当前对象存储集群正常,客户端与存储集群连接正常,客户端可以正常读写文件。
6. 集群卸载
删除集群很简单,但也容易删除不干净,主要包括:卸载 ceph 软件、清除磁盘数据、删除逻辑卷。
6.1. 卸载 ceph 软件
在 admin 节点上执行以下命令:
ceph-deploy purge node0 node1 node2
该命令将会卸载 node0 node1 node2 节点中 ceph 相关的所有软件,可以同时指定多个 hostname。
6.2. 删除数据
在 admin 节点上执行以下命令:
ceph-deploy purgedata node1 node2 node3
该命令将会清除 node0 node1 node2 节点中 ceph 所有配置文件和数据文件,可以同时指定多个 hostname。
6.3. 删除密钥
在 admin 节点上执行以下命令:
ceph-deploy forgetkeys
该命令将会从 rados 中删除部署集群时添加的所有 auth key。
6.4. 删除逻辑卷
ceph-deploy 在创建 osd 时,会将每个 osd 对应的硬盘以逻辑卷的形式挂在到系统中。上面删除操作并没有将 osd 对应的逻辑卷删掉。如果下次再重新部署集群时,可能会因为逻辑卷冲突导致 osd 创建失败。删除 osd 对应的逻辑卷方法也有很多,可以使用 ceph-volume 工具,也可以使用 vgremove 手动删除。本文将采用 ceph-volume 方式。
在集群中所有部署了 osd 服务的节点上执行以下命令:
ceph-volume lvm zap --osd-id 0
ceph-volume lvm zap 命令只是一个本地操作,无法操作其他节点的 osd。因此,上述命令只会将 node0 节点上的 osd.0 对应的逻辑卷从系统中彻底删除,因为 osd.0 在 node0 节点上。
7. 参考资料
- https://docs.ceph.com/en/octopus/start/os-recommendations
- https://docs.ceph.com/en/nautilus/start
- https://docs.ceph.com/en/nautilus/rbd/rados-rbd-cmds
- https://docs.ceph.com/en/nautilus/cephfs/createfs
- https://docs.ceph.com/en/nautilus/cephfs/fuse
- https://docs.ceph.com/en/nautilus/install/install-ceph-gateway